Web-scale search engine platform
Siets Global Internet Crawler spidering software, accompanying Siets Server, uses generic Siets
Server clustering capacity to index and store massive volumes of data
needed for establishing and operation of a country-wide or a global
scale Internet search engine.
Siets Server handles large capacity of multi-lingual web data with a less
number of servers due to its all-in-one platform design architecture.
If you are running a large scale country-wide or a global Internet search engine, by replacing existing resource demanding systems and by
installing Siets software technology you can save more than 50% from the current administrative and maintenance costs.
Subsections below describe in more details how Siets Global Internet Crawler can benefit from distributed cluster architecture deployments.
Web scale search requires large cluster deployment
By joining several Siets Server computers in cluster configuration it is possible to increase indexing performance several times.
Total time needed for indexing of all data will be decreased proportionally to the total number of cluster computers.
See figures below where it has been illustrated.

Figure 1. Indexing of large text collections on a single server computer can take many hours.
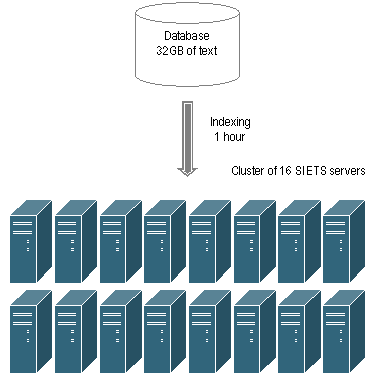
Figure 2. Siets Server indexing performance can be scaled linearly using multiple cluster computers
to reduce indexing times for large document collections.
This approach greatly benefits many applications where search database can be split among multiple computers.
Large scale Internet crawling and indexing use case is the best example.
Major Internet search engines use the system of distributed crawlers and indexers based on cluster configuration.
Siets Server was designed to allow to implement Internet search applications in similar way.
Split the entire web index into smaller parts
Using Siets cluster configuration, the full database update frequency can be increased substantially because
complete updates are needed for parts of the database which are relatively small.
Internet crawler and search applications frequently need to update their search databases and search indexes.
So does Siets Global Internet Crawler software.
In case of very large data sets such indexing can be done once per day or per week depending on how many
servers work in parallel in the cluster.
Never-lost reliability if some data is missing
Clever clustering can provide for higher business availability of search and indexing services.
In case of malfunction of a server in the cluster the system as whole continues to operate.
Search results are being received and processed from the rest of working servers.
Siets Global Internet Crawler software is doing the same.
There will be missing some documents in the search results from the malfunctioning server.
Nevertheless until the problem will be fixed the search service to end-users will continue to work.
In this way corporations can avoid total service interruption.
Internet search applications can greatly benefit from this cluster enabled fault tolerance against
total service disruptions.
End-users almost never discover that some documents from search results are missing.
Even if some end-users suspect some missing data and retry the same search later,
service provider has time to replace the malfunctioning server and restore backup copy of the missing data.
Generally there will be little or no customer complaints about service unavailability and higher quality
of end user experience using business search services running in cluster environments.
Most leading Internet search engines are operating in similar way, using generic fault tolerance of cluster environment.
Siets Global Internet Crawler software is doing the same.
Asymmetric distribution of index updates
Besides symmetric data distribution among all cluster nodes or replicas, it is possible to implement asymmetric data
distribution for indexing of very large data sets in cluster configurations.
The asymmetrical indexing method can be used when large portion of data should be updated relatively
less frequently than other smaller portion of data.
In this case the largest data set with seldom updates should be indexed on one cluster server,
and small data set with frequent updates should be indexed on the other cluster server.
This solution has two-fold benefits. First is the economy of resources because all frequent updates are being
done for the database of rather small size, which provides higher total performance of the system and less frequent disk equipment reads/writes.
Secondly, this is higher reliability environment: there are much less chances to break something
due to equipment malfunctioning or software errors in a relatively small data set that is being modified.
Typically archived data portions do not change at all but occupy most of the resources.
Even if the smaller portion of data on one cluster node will be damaged, the largest archived data
portion on other nodes should not be even re-indexed.
Savings can be tens and even hundreds of hours of working time on maintaining the large database updates.
Organized data store for efficient backups
Similar efficiency savings are for performing data backup copying and restoring.
In cluster configuration with organized data distribution (known location per nodes)
backup and restore tasks require much less time from system administrators compared to one large database or a distributed database where
location of data per cluster nodes is not known.
Initial backup copy for the large unchanging archived portion of the
data can be made immediately after its creation on one of the cluster servers.
Backup for the smaller frequently changing data on other cluster server can be made as frequently as needed,
for example, every day or even every hour small database size does not require a lot of resources to do it.
The same time savings are present when it is needed to restore full working database from the backup copies.
Mostly only smaller size backup copy will be needed to restore in case of problems.
This kind of clustering solution is the most crucial for building Internet search solutions that can be reliably and quickly
serviced for such mundane tasks as backup, recovery, replacement upon hardware repair, and incremental web site data updating.
Automatic cluster balancing tools in some other search products sounds a good solution, unfortunately those products
fail to scale on web-scale tasks since any intelligent update operations on data become too expensive.
The controlled management of database parts by organizing clever application-driven data distribution across large cluster
is not an obvious Siets Server cluster software advantage at the first glance.
Therefore let's imagine backup or a recovery task of a single website with some small set of 100 pages
in a billion document database cluster on 100 servers. When one does not even know which server out of 100 to approach to do this
pretty frequent in web search backup task, the only solution available is to back up / restore either all 100 server data or to do a cluster-wide search
for every document and then update one by one, overloading all 100 servers and network with unnecessary traffic and indexing job on all servers.
More problems come after: all 100 servers needs to be fully backed up again to reflect consistent search results after just this one
smallish web site update. This type of escalating search index consistency maintenance nightmare quickly becomes unmanageable problem
where automatic distribution of data across all cluster nodes is performed by search engine platform.
This is key reason why Siets Server software does not automatically rebalance and redistribute data in cluster, unbeknownst to the application owner.
Siets Global Internet Crawler software does controlled data partitioning for website data collected to avoid problems of "automatic data rebalancing"
that ruins scalability at very large scale.
Save by using commodity off-the-shelf hardware
Distributing a large web search database among several cluster computers, each hardware computer can be
having less expensive and simple hardware specifications compared to the heavy-duty power-server situation,
when the entire database runs on a single powerful server computer.
For example, suppose a database is running on an enterprise level 2-processor Xeon server with SCSI RAID disk array with 2GB RAM memory.
About the same cost will be to install 4-5 more custom computers (1-Pentium processor, 1GB RAM, no RAID, one fast 80GB IDE or SATA disk)
and use them in cluster configuration.
In this way organizations can have all above mentioned cluster benefits which will not be available
if the whole database are running on a single and powerful server.
Making hardware upgrade cost-efficient and easy
Great benefit of clustering on many low-cost hardware is upgrade scalability.
In order to increase data volumes there is no need to look for possibilities how to upgrade existing enterprise server
or how to replace it with more powerful hardware. Enterprise server upgrades in
combination of RAID/SCSI disk equipment usually are substantial expenses for every corporation.
Another inconvenience of big powerful servers is need to stop all services in case of hardware upgrades
while hardware components are being replaced and reconfigured.
Very often it causes unnecessary business service unavailability not only for the primary application but for
some other business applications running on the same server.
On the contrary, if the system already works in the cluster configuration,
it is sufficient to add a new relatively custom (commodity) computer to the existing cluster and start to store additional new
data on the new cluster node without any service interruptions.
Scale out vs scale up cost-efficiency
Another problem of large servers are their technical scalability limits. Their upgrade options usually are limited physically.
One can not put more memory or more disk devices than a server equipment manufacturer has reserved as
free physical space for limited upgrade needs in a single server.
Cluster hardware environment can be easily upgraded up to tens and even hundreds of computers,
creating in this way computing platform with giant workload capability and reliability.
This principle is used by many leading Internet search portals.
Interchangeable use of hardware
Replacement of outdated hardware is less problematic in cluster environments compared with big server environments.
Large technically outdated enterprise servers are hard to reconfigure for other use.
Outdated cluster servers can still serve as employee PCs.
Simplify support with inexpensive hardware
In cluster environments administrators do not spend their time for installation and configuration of large enterprise servers.
It can be time consuming process because of many differences between enterprise server models, proprietary device drivers etc.
Every cluster hardware equipment is relatively simple computer and can be installed and configured in about 20-30 minutes.
Time is being saved both for installations in the data center environment and solving of technical problems of cluster nodes.
Commodity hardware can be served by technically less skilled people.
Manage very large databases cost-efficiently
All of techniques described above for running web-scale Internet crawling and search service as a reliable 365/24 operation
can be also applied to your corporate data volumes of giant size.











