This section describes SIETS document structure concepts and explains strategies, if source data that you want to import into the SIETS system, are unstructured, and if the source data are XML structured. It also describes document ordering and language and text encoding concepts.
This section contains the following topics:
As mentioned previously, any data can be stored in the SIETS system and then retrieved using FTS queries. Data are stored in the SIETS storage as SIETS documents. A SIETS document is the smallest unit in the SIETS storage against which searching is performed. When a search request is submitted, the SIETS server searches within the SIETS storage and finds all documents that match the query.
Abstracting from specific content, format, and structure, we assume that data in existing corporate filings, databases, or storages can be perceived as documents that each have a unique ID, title, and a content consisting of textual and possibly XML marked up information in which FTS can be performed.
An ID can be a simple integer, an alphanumeric character string, a full file path on a file server and the file name, a URL of a Web page, or any other element that uniquely identifies a document.
Often there are also other elements; however, we will talk about them later. Also we assume that when performing a search request, what a user expects to have as a reply is a list of IDs, titles and short descriptions of those documents, which match the search request.
The SIETS system supports the assumed default elements for importing and retrieving data.
The following sections describe how documents are imported in the SIETS system if they are not XML structured and if they are XML structured.
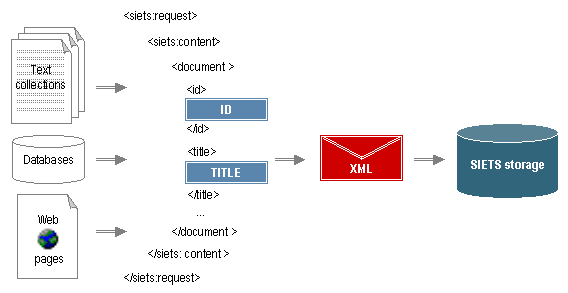
When importing data to the SIETS storage using the SIETS API functions, the default document elements: ID, title, and content, are passed to the SIETS server as parameters of respective functions. When calling respective SIETS API command for storing a document in the SIETS storage, elements of the document are enclosed in XML tags and sent to the SIETS storage.
The following figure illustrates this process:
Figure 10: Storing data in the SIETS storage
The following table lists and describes all default elements for a SIETS document.
|
Element |
Description |
|---|---|
|
ID |
Unique document identifier in which FTS is not performed. |
|
Title |
Document title in which FTS can be performed. |
|
Rate |
Value of the integer type in which FTS is not performed assigned to a document with a respect to other documents. When performing a search request, search results will be ordered by rate, if not by relevance. For more information on document ordering, see Document Ordering in Result Set. |
|
Domain |
Document domain. This element can be used to denote a domain of a Web document, as well as, it can be used as a classifier for any kind of documents. When performing a search, it is possible to limit the number of documents from one domain in the search result. |
|
Text |
Textual information in which FTS can be performed. SIETS also supports XML marked up information and preserves the markup, when searching in it. A snippet, which is a fragment with an occurrence of the search term, is returned to the search results. |
|
Hidden |
Textual information in which FTS can be performed, but for which a snippet is not returned to the search results. |
|
Info |
Additional information added to a document, but in which FTS is not performed, for example, picture files, MS Word or PDF document files, and so on. Note that these files must be appropriately formatted. For information on appropriate formatting, see Formatting XML Special Characters. |
Extracting and defining these elements from source data before importing the data to the SIETS system is an application task.
If source data are XML structured, it is not necessary to restructure it
to the default
SIETS document structure described in the previous section. SIETS uses the document structure definition mechanism, called scheme, to
define the location and behavior for each document part. Before you can
store the XML structured source data to the
SIETS storage, the scheme for the SIETS storage must be defined. The existing scheme is retrieved and a new
scheme is set to the
SIETS storage by calling the SIETS API commands get_scheme and set_scheme, respectively, which use XPath notation to define a location and to
assign one or more policies to each document part.
For more information on the Xpath notation, see http://www.w3.org/TR/xpath.
By policy we understand a set of operations for data importing and
retrieving to the
SIETS storage. All policies apply to all document parts. However, each policy
has a set of values, which define, to what extend does the policy apply
to the document part. Each policy can have a different value set for the
particular document part, for example, the policy
id=no, which means that information of this document part will not be considered as
the document identification part, and the policy
index=all, which means that information of this document part will be indexed
both: as textual information and also as textual information with
preserved XML
markup.
The following table lists all policies with their values. The first value listed for a policy is the default value, in other words, the value that are set if the policy is not specified for the document part.
|
Policy |
Value |
Description |
|
|---|---|---|---|
|
id |
no (default) |
Information within this part will be not considered as identifier of the document. The policy is not applied to this document part. |
|
|
yes |
Information within this part will be considered as identifier of the document. |
||
|
rate |
no (default) |
Information within part will be not considered as rate of the document. |
|
|
yes |
An integer number within this part will be considered as rate of the document. |
||
|
domain |
no (default) |
Information within this part does not denote a domain of a Web document, or any other classifier of a document. |
|
|
yes |
Information within this part is denotes a domain of a Web document, as well as, a classifier for any kind of documents. |
||
|
index |
no (default) |
Information within this part will be stored in the document repository and available for retrieval, however, it will be not indexed in the inverted index. |
|
|
text |
Textual information contained within this part is added to the inverted index and made available for FTS. |
||
|
xml |
Textual information contained within this part preserving XML markup is added to the inverted index. In this case FTS will be performed according to the XML markup. |
||
|
all |
The two above applies to this document part. It consumes more resources of memory and longer indexing time. |
||
|
classify |
This index type is used for categorizing documents in some type of hierarchy, for example directory structure. Data later can be accessed using XPath expressions, relative to this part. Only one part can be set as index classify for document. See more information in chapter on XML drilldown. |
||
|
weight |
<min–max> |
This policy works only together with the |
|
|
list |
no (default) |
Information within this part will be not listed in the search results. |
|
|
yes |
Information within this part will be listed in the search results. |
||
|
highlight |
Information within this part will be listed in the search results, but the search terms within this part will be highlighted. |
||
|
snippet |
In the search results, from this part only a snippet will be shown. The search terms within this part will be highlighted. |
Technically, there are two ways, how to set policy values for document parts:
by calling the SIETS API command set_scheme, which sets the policy value for the document part for all documents in
the SIETS
storage
by adding the siets:policy attribute to a document part tag element, for example, <title siets:index=”text”>, which sets the policy value for the document part for a particular
document
For more information on the get_scheme and set_scheme commands, see Get_scheme and Set_scheme.
It is suggested to assign policy values by calling the SIETS API commands get_scheme and set_scheme as this option is easier and faster.
However, adding the siets:policy attribute to a document part tag element is more powerful in cases when
each document in the
SIETS storage you want to define a different policy values for the document
parts. For example, for one document the
index policy can be set to all, while for other documents in the same SIETS storage the index policy can be set to text.
These two mechanisms can be combined, for example, you can store all
documents with a single policy value for the document part to the
SIETS storage, and then for some documents from the SIETS storage add the siets:policy attribute to a different value.
In SIETS future releases the list of predefined policies can be expanded.
This section describes how documents are ordered in a result set. It describes the two mechanisms conceptually and contains the following topics:
There are two mechanisms in the SIETS system how documents are ordered in a result set:
By rate, which must be assigned by the application to each document before storing it to the SIETS storage and is independent from a search request.
By relevance, which is calculated when performing a search and which ensures that documents that are closer to a search request, are displayed first in a result set.
The rate ensures high performance of the search function, the relevance ensure the quality of the search results. Sorting by rate is a default mechanism that is applied every time a search is performed. Sorting by relevance is an option that you can choose additionally when a search is performed.
The decrease of performance due to the relevance is minimal.
The rate and relevance mechanisms are illustrated by an example in the following figure:
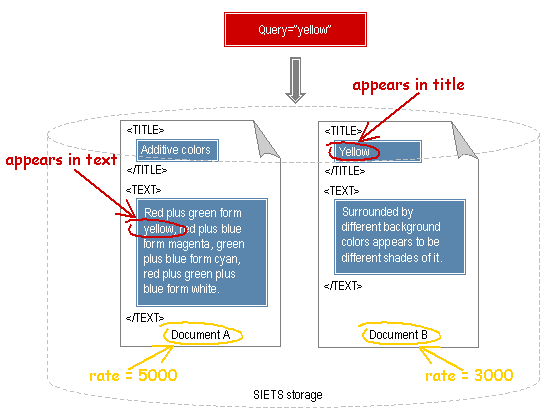
Figure 11: Document rate and relevance
The query contains the search function that must return documents containing the word yellow.
Each document in the SIETS storage has the rate assigned: the document A has a rate=5000, and the document B has the rate=3000.
The following table presents the sequence of the two documents in the result set, when the search function uses the relevance for document ordering, and when it does not, in other words, when the relevance is on and when the relevance is off.
|
Document and its rate |
Relevance off |
Relevance on |
|---|---|---|
|
Document A rate=5000 |
1 |
2 |
|
Document B rate=3000 |
2 |
1 |
When searching with the relevance off, only the document rate is considered, and, therefore, documents with higher rates are displayed first. In the example, the document A has a higher rate than the document B, and, therefore, the document A is displayed first.
When searching with the relevance on, place where the search term appears in the document is considered, and, therefore, documents that contain the search term in parts that are more important than other parts, in other words, have a higher specific weight, are displayed first. In the example, the document A contains the search term in its text part, whereas the document B contains the search term in the document title, which has the higher specific weight than the text. Therefore, the document B is displayed first.
The rate is a number of the integer type in the range from 0 to 4294967295=232-1, which must be assigned by the application to each document when storing it to the SIETS storage.
The rate allows significant optimizations for large data amounts, which ensures high performance of the SIETS system.
It is an application developer’s task to create an effective algorithm for assigning rate to document collections that is appropriate and satisfies user needs, for example, alphabetic order, by document publication or creation date, or objective document importance.
If the rate is not assigned or if there are documents with the same rate, the default document order in a result set is a reverse of the document storing sequence to the SIETS storage.
In a single SIETS storage, only one rate-assigning algorithm can be used.
If your application requires several ordering types for one document collection, then you must create several SIETS storages, which each contains the document collection with its own rate-assigning algorithm.
Technically, assigning the rate to documents is setting an integer value
for the
rate element. For more information on the SIETS document structure, see Creating Document Structure with Application.
The relevance is a number of the integer type, that is a measure of the accuracy of the search results, which is calculated according to:
the specific weight interval of the document part in which the search term appears
the number of times the search term appears compared to other documents
the distance between the search terms in the document, if multiple words are being searched
A document partwith a higher specific weight interval than other document parts mean that this part is considered as more important than the other parts. For example, the document title is more important than the document text.
In the SIETS system, there is a relevance calculation algorithm, which is implemented according to the three items described above in this section.
However, the first item: the specific weight interval can be customized to best reflect your document structure.
Fore more information on the SIETS relevance calculation algorithm, see Relevance Calculation Algorithm.
Fore more information on setting your own specific weight, see Customizing Specific Weight Interval.
This section describes general principles of the SIETS relevance calculation algorithm.
Note: This section contains some of SIETS system implementation details. Description provided in this section is very general and does not include implementation details for all SIETS functionality.
The SIETS relevance calculation algorithm consists of two parts that are performed when:
storing documents to the SIETS storage
searching documents in the SIETS storage
Steps of the SIETS relevance calculation algorithm are described generally. To ensure a better understanding of the algorithm, an example is also provided. Each step is followed by the example part that reflects the step.
When storing documents to the SIETS storage, specific weight for each word in a document is calculated as follows:
1.1 In each document part, the specific weight is calculated for each word according to the specific weight interval of the document part the word occurs.
The specific weight for a word in a document part is the minimum value of the following:
minimum value of the specific weight interval of the document part plus a number of times the word occurs in the document part
maximum value of the specific weight interval of the document part
Note: The specific weight interval minimum and maximum can be the same value. In that case, for all words in such document part, no matter how often they appear, the specific weight in the document part is the same: the specific weight value of the document part.
1.2 The maximum value of specific weights of a word in all document parts is assigned as the specific weight of the word in the document.
Example:
A document consists of three document parts: heading, description, and note. Each document part contains words w1, w2, and w3 and has its own specific weight interval, as described in the following figure:
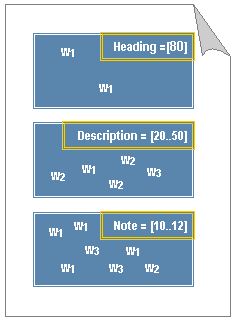
Figure 12: Calculating specific weight for each document
w1(heading)=min(80,80)=80, w1(description)=min(20+1,50)=21, w1(note)=min(10+4,12)=12
w2(heading)=0, w2(description)=min(20+3,50)=23, w2 (note) min(10+1,12)=11
w3(heading)=0, w3(description)=min(20+1,50)=21, w3 (note) min(10+2,12)=12
Example (continued):
max(w1(heading), w1(description), w1(note))=80
max(w2(heading), w2(description), w2(note))=23
max(w3(heading), w3(description), w3(note))=21
When searching documents in the SIETS storage, the relevance of the document according to the search request is calculated as follows:
2.1 Specific weights of all search terms in a document are summed.
2.2 The relevance is calculated by multiplying the sum from the previous step with a value that is calculated taking into the account the distance between the search terms in the document: the greater the distance, the smaller the value
Example (continued):
Σ(w1, w2, w3) = max(w1(heading), w1(description), w1(note)) + max(w2(heading), w2(description), w2(note)) + max(w3(heading), w3(description), w3(note)) = 124
Example (continued):
Relevance = Σ(w1, w2, w3) * d
This section describes how to set specific weight interval for document parts that best reflects your document structure.
As described in the previous section, a specific weight interval for a document part is an interval between two integer numbers.
By default, the following specific weights are defined:
|
Document part |
Minimum |
Maximum |
|---|---|---|
|
Title |
100 |
100 |
|
All except Title |
1 |
99 |
You can set a different value for the title part, and you can define a
separate specific weight interval for each document part, such as
Text and Hidden, or other document parts that you have, to ensured more detailed
relevance
calculation.
Because of the performance considerations, there is a limit for the maximum specific weight interval value, which is 255.
Technically, there are two ways, how to customize specific weight intervals for document parts:
by calling the SIETS API command set_scheme, which sets the specific weight interval value for the document part
for all documents in the SIETS
storage
by adding the siets:weight attribute to a document part tag element, for example, <title siets:weigth=”75”>Title text</title>, which sets the specific weight interval value for the document part
for a particular
document
For more information on the get_scheme and set_scheme commands, see Get_scheme and Set_scheme.
It is suggested to assign specific weight interval by calling the SIETS API commands get_scheme and set_scheme as this option is easier and faster.
However, adding the siets:weight attribute to a document part tag element is more powerful in cases, when
for each document in the
SIETS storage you want to define a different set of specific weight intervals
for the document parts. For example, for one document the specific
weight interval of the title part can be set to 100, while for other
documents in the same
SIETS storage the specific weight interval of the title part can be set to
80.
These two mechanisms can be combined, for example, you can store all
documents with a single set of specific weight interval to the
SIETS storage, and then for some documents from the SIETS storage add the siets:weight attribute to a different value.