This section describes multi-language support and character encoding concepts, provides examples for different character encoding cases, and explains XML formatting concepts.
This section contains the following topics:
The SIETS API structure is based on XML, which means that all character encoding related issues adhere XML internationalization standards.
For more information on XML internationalization standards, see http://www.w3.org/TR/REC-xml.
SIETS provides a complete multi-language support, by automatically performing all necessary character encoding conversions.
You can import documents in different languages and encodings in a single SIETS storage, as well as you can perform search queries in different languages and encodings in a single SIETS storage.
This section contains the following topics:
Storing in Different Encodings and Searching in a Multiple Bytes per Character Encoding
Storing in Different Encodings and Searching in One Byte per Character Encoding
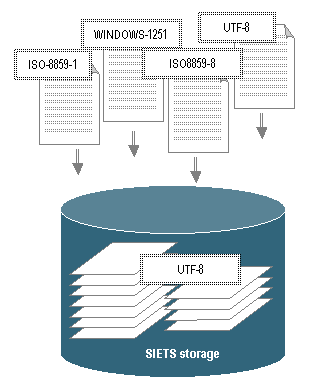
For document importing and searching SIETS supports any language and text encoding. When importing documents to the SIETS storage, internally, all documents are converted and stored in the UTF-8 encoding, as illustrated in the following figure:
Figure 13: Importing documents with different encodings
In Figure 13, document encodings are represented as encoding values each in a white box with a double dotted border.
Data exchange between an application and the SIETS server is performed in the XML format. In the XML format, data can be in any encoding; this encoding is defined in the XML header of the document.
All SIETS API functions have an encoding parameter, which defines the encoding of textual data. This encoding is used in the XML header, when importing documents to the SIETS storage as described in Creating Document Structure with Application. The textual data must comply with the encoding defined in a function parameter, or else the system returns a parsing error.
The number of encodings is only limited to those that are installed on a computer on which the SIETS server is run. To find out what encodings are installed on the SIETS server computer, see the SIETS Administration and Configuration Guide. For example, on RedHat Linux, usually, US-ASCII, ISO8859-1..13, WINDOWS-1250..1258, UTF-7, UTF-8, UTF-16, and UTF-32 encodings are installed.
Technically, only the encoding is important to the SIETS system, which means that you can store and search data in the SIETS system in any language as long as you supply a valid encoding for that language.
There are the following two types of encodings:
|
Title |
Description |
|---|---|
|
one byte per character |
Contains 256 characters, which means that, within one such encoding, characters for several similar languages can be included, for example, WINDOWS-1250 and ISO8853. |
|
multiple bytes per character |
Contains all UCS (universal character set) characters, which include characters for almost all languages, for example, Greek, Cyrillic, Korean, and so on. |
You can store documents in different languages with different encodings within a single SIETS storage; documents are converted to the UTF-8 encoding, which contains all characters from UCS and, therefore, all characters are preserved correctly.
Search results are returned in the encoding that is used for the search request.
The following three sections contain examples with different cases of working with a single and several encodings, which demonstrate the SIETS multi-language support.
This section contains an example, when a single encoding is used for document storing and retrieving.
The following figure illustrates the example:
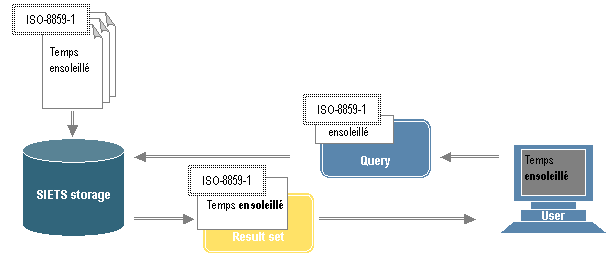
Figure 14: Storing and searching in single encoding
In Figure 14, document encodings are represented as encoding values each in a white box with a double dotted border.
All documents are imported to the SIETS storage in the same encoding.
In Figure 14, the encoding is ISO-8859-1 for French, which encodes
French character
é and other characters that are not included in a US-ASCII encoding.
Users submit search queries to the SIETS storage in the same encoding as the document source encoding.
Search results are returned to a result set in the same encoding.
The search results are displayed with correct characters to the user.
Note: The user computer must have appropriate fonts installed for viewing that
encoding. Older browser versions may not support the UTF-8 encoding and
display the special characters as question marks
?. In that case, the browser must be updated.
This section contains an example, when different encodings are used for document storing and a multiple bytes per character encoding is used for retrieval.
The following figure illustrates the example:
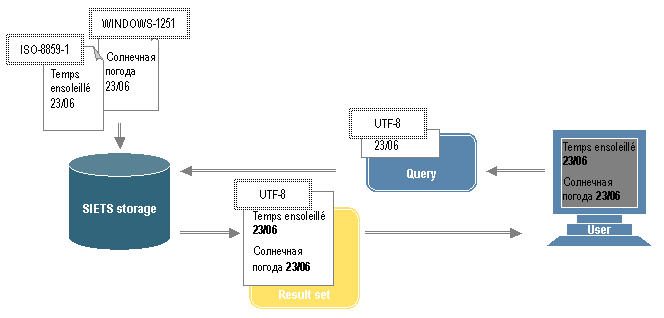
Figure 15: Storing in different encodings and searching in multiple bytes per character encoding
In Figure 15, document encodings are represented as encoding values each in a white box with a double dotted border.
Documents are imported to the SIETS storage in different encodings. In Figure 15, the encodings are ISO-8859-1 for French and WINDOWS-1251 for Russian.
Users submit search queries to the SIETS storage in a multiple bytes per character encoding, in Figure 15, the encoding is UTF-8.
Search results are returned to a result set in the encoding, which is used in the search request, in Figure 15, the encoding is UTF-8.
As in this case the multiple bytes per character encoding is used, there are no problems for displaying characters for both languages.
The search results are displayed with correct characters to the user.
Note: The user computer must have appropriate fonts installed for viewing that
encoding. Older browser versions may not support the UTF-8 encoding and
display the special characters as question marks
?. In that case, the browser must be updated.
This section contains an example, when different encodings are used for document storing and a one byte per character encoding is used for retrieval.
The following figure illustrates the example:
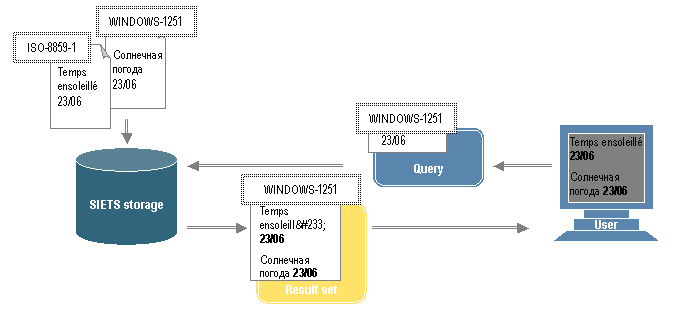
Figure 16: Storing in different encodings and searching in one byte per character encoding
In Figure 16, document encodings are represented as encoding values each in a white box with a double dotted border.
Documents are imported to the SIETS storage in different encodings. In Figure 16, the encodings are ISO-8859-1 for French and WINDOWS-1251 for Russian.
Users submit search queries to the SIETS storage in a one byte per character encoding, in Figure 16, the encoding is for Russian.
Search results are returned to a result set in the encoding, which is used in the search request, in Figure 16, the encoding is for Russian.
Characters that are not in the encoding are returned as XML entities, in
Figure 16, the French symbol é is returned as é.
For more information on XML entities, see http://www.w3.org/TR/REC-xml.
The search results are displayed with correct characters to the user.
Note: The user computer must have appropriate fonts installed for viewing that
encoding. Older browser versions may not support the UTF-8 encoding and
display the special characters as question marks
?. In that case, the browser must be updated.
As mentioned in earlier sections, data are sent from an application to
the
SIETS storage in the XML formatting. Therefore, the data must comply with XML
formatting rules, for example, the data cannot contain XML special
characterslike <, >, and &, which are used for the XML markup, instead, <, >, and & must be used respectively.
Example:
If you have a title A&B, you must convert it to A&B.
For more information on the XML formatting rules, see http://www.w3.org/TR/REC-xml.