This section contains the following topics:
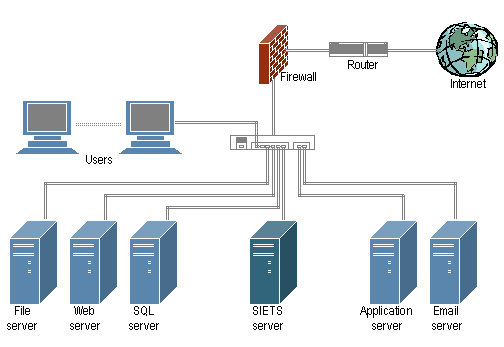
SIETS system can be integrated into an existing corporate network system. The SIETS server is incorporated into the network system just like any other server. The following figure describes a sample corporate network with the SIETS server.
Figure 2: SIETS server in a corporate network
Application servers and transaction processors from an existing corporate network can access the SIETS server as active SIETS API clients; in that case, for security reasons, end users cannot directly access the SIETS server. In that way, SIETS server can be used in any corporate network, independently from the operation system, database environment, or programming language used for application development.
The SIETS server is software that is installed on an Unix-like operating system, for example, RedHat Linux.
In the sample presented in Figure 2, the SIETS server is installed on a single separate computer.
It is possible to install and run the SIETS server on the same computer with other services, such as Web server and application server. However, there are the following issues, if having the SIETS server installed and run on the same computer with other services:
For large data amounts, the SIETS server intensively uses disk input and output and CPU resources, which may interrupt other services, and vice versa: other services can reduce performance of the SIETS server.
Problem tracking becomes more complicate.
For very large data amounts, SIETS supports sever clustering, which ensures performance scalability.
For more information on SIETS server multi-server architecture, see Multi-Server Architecture.
As already described in the previous section, the SIETS system is used for data storage and retrieval. The SIETS system is an environment for executing data storage and retrieval commands, which are called from applications. The commands are understood and executed by the SIETS server. The applications are written by application developers. For more information on developing applications for the SIETS server, see the SIETS Developer’s Guide.
This section describes SIETS from various architectural perspectives.
This section contains the following topics:
The following figure describes SIETS architecture from user roles perspective:
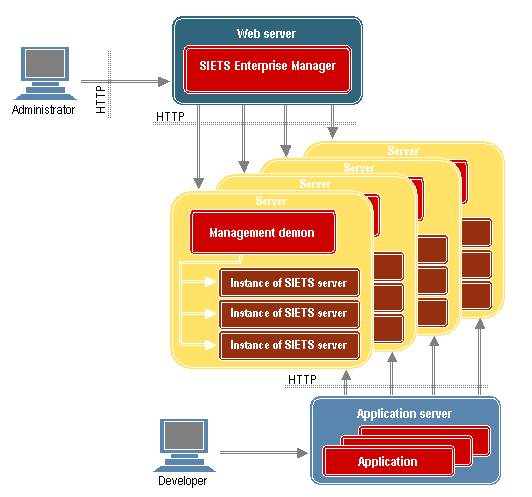
Figure 3: SIETS architecture from user roles perspective
SIETS administrator uses SIETS Enterprise Manager to administer SIETS servers. SIETS Enterprise Manager is a CGI executable installed on a Web server, which allows configuring SIETS server parameters and options. After parameters and options are configured, they are automatically submitted to the management demon of each SIETS server.
This ensures that performing SIETS administering tasks is convenient and can be done remotely.
Developers create applications, which are run on an application server, which initializes SIETS API command calls and sends them to SIETS servers via HTTP.
In Figure 3, for a better understanding of roles, the Web server and application server are on separate computers. However, the Web server and application server can be on the same computer.
The following figure describes how multiple SIETS server instances can be run on a single SIETS server:
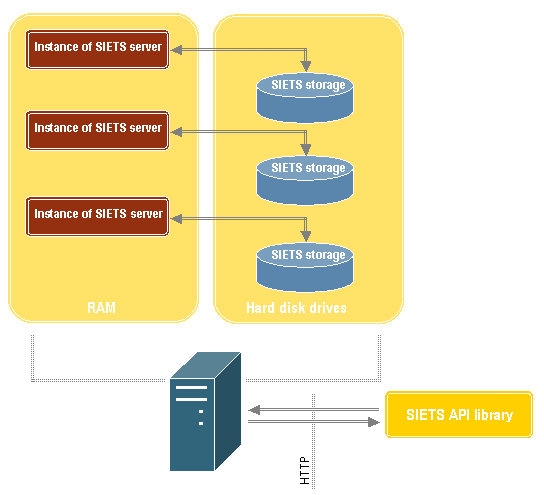
Figure 4: SIETS multiple storages architecture
Multiple instances of the SIETS server can be run on a single computer, which each works with its own SIETS storage.
To ensure scalability of larger amounts of data, the SIETS server can be clustered sharing a single SIETS storage across many computers.
The following figure describes how a single SIETS storage can be distributed on several SIETS servers:
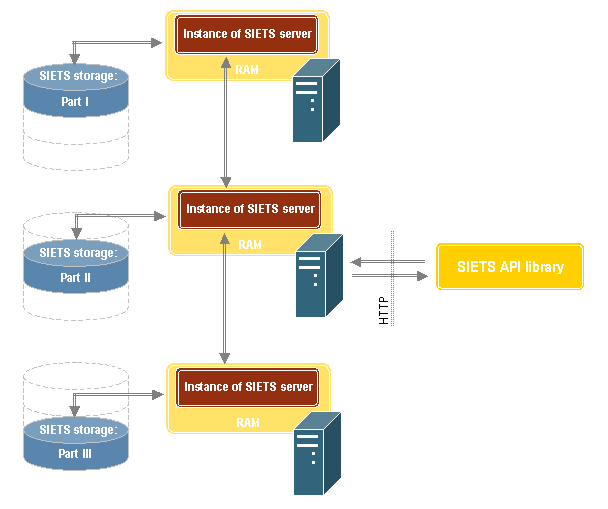
Figure 5: SIETS multi-server architecture
This section contains the following topics:
Full text search (FTS) is a data selection mechanism, which returns a document set containing words in a definite logical combination from a text collection.
Example:
|
Document Nr. |
Text collection in document |
|---|---|
|
1 |
sun, rain, cloud |
|
2 |
sun, rain |
|
3 |
cloud, snow, storm |
|
4 |
rain, hail |
|
Search request |
Documents returned |
|---|---|
|
rain |
<1, 2, 4> |
|
sun AND cloud |
<1> |
|
storm OR hail |
<3, 4> |
|
rain AND (cloud OR hail) |
<1,4> |
|
rain NOT sun |
<4> |
Inverted index is a list of words, where each word has a list of pointers to SIETS documents in which the word occurs.
Example:
In the example from the previous section, the inverted index is as follows:
|
Word |
Documents in which word appears |
|---|---|
|
sun |
1, 2 |
|
rain |
1, 2, 4 |
|
cloud |
1, 3 |
|
snow |
4 |
|
storm |
4 |
|
hail |
5 |
What is the use of the inverted index in FTS? Let us assume that in the example we need to find documents containing the word “cloud”. To do that, we only need to find and read an entry in the inverted index, which doubtless is much faster operation than scanning the whole text collection. Now, let us assume that in the example we need to find documents containing the word “cloud” AND “snow”. To do that, we need to find entries in the inverted index and perform the set intersection operation, which also is a relatively simple and fast operation. For other logical expressions between the search terms other set operations are performed.
In reality, FTS algorithms are more complex since usually additional functionality is added, such as sorting search results by relevance according to the search query, searching for exact phrases and so on. However, the inverted index is the basis for efficient FTS.
A text collection can be considered as a document set, where each document consists of a set of words contained by the document, in other words, a relation <document, word>. Initially, on the disk, this set is ordered by documents. To construct the inverted index, the list must be sorted by words.
In that way, pointers to documents in which a word appears are adjacent on the disk and, therefore, can be used for searching effectively on a disk equipment using electromechanical storage technologies, for example, hard drives with mechanical disk heads.
Example:
Document sample:
| <1, sun> <1, rain> <1, cloud> | <2, sun> <2, rain> | <3, cloud> <3, snow> <3, storm> | <4, rain> <4, hail> |
Invert to the following index sample:
<1, sun> <2, sun> <1, rain> <2, rain> <4, rain> <1, cloud> <3, cloud> <3, snow> <3, storm> <4, hail>
Thus, after the document collection is loaded in the SIETS system, it is necessary to construct the inverted index. For large data amounts, this operation can be time consuming, because, although the algorithm is relatively simple, for data amounts exceeding RAM, the disk head movement is increased and can cause performance bottleneck.
In real life, rarely you have to perform FTS in a fixed data collection. This means that usually the inverted index construction is performed on a quite regular basis, which is why it should be maximally invisible to users. In SIETS the inverted index construction algorithm is designed with many rational and effective optimizations to achieve high performance, the following of which are visible and must be understood by the SIETS administrator:
If the memory reserved for memory cache is enough for the data amount
being imported, a special cache, which is located in RAM, is used for
indexing. This ensures that documents are available for FTS immediately
and users do not notice the indexing process. In this case the status of
a storage parameter
/status/matrix/pool_state = normal. The pool_state parameter can be retrieved when performing status monitoring. For more
information on status monitoring, see
Monitoring SIETS Storage Status and Logs.
If the memory reserved for memory cache is not enough for the data amount being imported, a secondary level cache, which is located on the disk, is used for indexing. This means that during the indexing process some documents being indexed may not be available for FTS. In this case the status of a storage parameter is one of the following:
|
State |
Description |
|---|---|
|
|
Data are being added to the cache. |
|
|
Data from the cache are being committed to the inverted index. |
The pool_state parameter can be retrieved when performing status monitoring. For more
information on status monitoring, see
Monitoring SIETS Storage Status and Logs.
According to the description of inverted index and its construction algorithm in previous sections, the following guidelines are recommended for SIETS administrator, when helping application developers to find the best strategy for performing indexing in the SIETS storage:
Do not start any document adding, deleting, or updating command while
the SIETS server is indexing the previous portion of documents and the
pool_state parameter is collapsing. In other words, start document adding, deleting, or updating commands
when the
pool_state parameter is normal and the disk cache is not being used for indexing.
If the disk cache is used very intensively for indexing on regular basis, consider adding more memory to the computer you have the SIETS server installed on. An exception, when an intense cache usage is considered as normal, is when you first import a large data amount to a newly created SIETS storage from an existing data source.
Develop applications so that they do not use the disk cache intensively, to avoid slow performance.
Indexing data can take two to four times longer period than copying such data amount on the disk. Generally, it is assumed that the number is four, and it must be considered, when developing applications. The indexing time depends on application and data amount.
| Previous | Top | Next |